Recently, Assoc. Prof. Hu Bing’s group, in collaboration with iDC-NEU Lab at Northeastern University, the University of Surrey, and Zhongguancun Academy, made significant progress in efficient cloud-edge collaborative inference for large language models (LLMs). Their work, titled “PipeSD: An Efficient Cloud-Edge Collaborative Pipeline Inference Framework with Speculative Decoding,” has been accepted by the 43rd International Conference on Machine Learning (ICML 2026). PhD candidates Han Yunhe and Gao Yunqi are co-first authors, with Assoc. Prof. Hu Bing serving as the sole corresponding author.
As LLMs become widely deployed across various scenarios including intelligent terminals, code generation, mathematical reasoning, and content creation, low latency, high energy efficiency, and deployability have become critical challenges. Existing LLM inference typically relies on token-by-token autoregressive generation, which presents an inherent serial bottleneck. Speculative decoding—where a smaller draft model generates candidate tokens that are then verified by a larger target model—has emerged as a default optimization technique for many mainstream LLMs while preserving output quality. The inference paradigm of SD is naturally suited for cloud-edge collaborative scenarios and enables effective offloading of cloud workloads, user privacy protection, and improved offline availability.
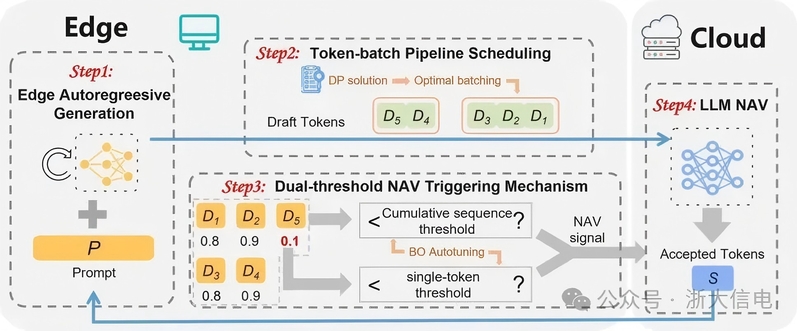
However, existing SD frameworks face two core challenges in cloud-edge settings: first, the computation and communication processes of the draft model at the edge are often executed sequentially, resulting in low utilization of edge computing power and network bandwidth; second, the verification triggering mechanism for the target model on the cloud is insufficiently flexible, often leading to premature or excessive verification that impacts overall inference efficiency.
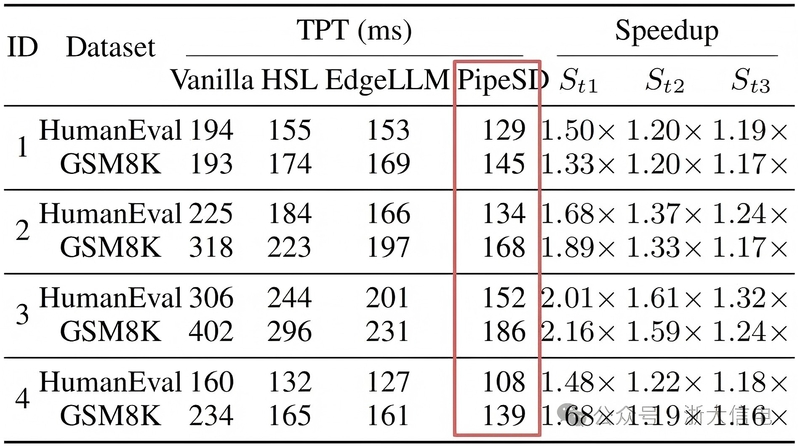
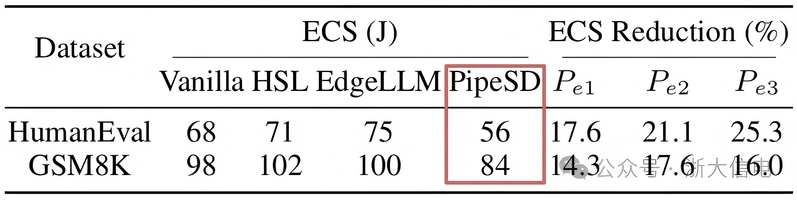
Assoc. Prof. Hu’s group proposed the PipeSD framework—an efficient, scalable pipeline speculative decoding framework for cloud-edge collaborative inference. Through a pipelined speculative decoding mechanism, a dynamic programming-based token-batch scheduling strategy, a dual-threshold verification triggering mechanism, and a Bayesian adaptive tuner, PipeSD achieves deep synergy among edge token generation, cloud-edge communication, and cloud verification, significantly improving the efficiency and energy performance of LLM inference in cloud-edge scenarios. Experimental results show that PipeSD achieves 1.16× to 2.16× inference acceleration and reduces cloud energy consumption by 14.3% to 25.3% under varying edge computing capacities and dynamic network bandwidth conditions, offering a new technical pathway for addressing the communication bottleneck, resource idling, and verification inefficiency challenges in edge deployment of LLMs.
ICML is one of the most prestigious top-tier conferences in global machine learning and AI, classified as a CCF Category A conference. For ICML 2026, 23,918 full papers were submitted to the main conference, with 6,352 accepted at an acceptance rate of 26.6%.
